Data Collection for Containers
Data Collection for Containers
#410140
Densify can collect and analyze your container configuration and utilization data and then provide recommendations for optimizing your container-based applications.
Densify's container data collection consists of:
- Deploying the Densify Data Forwarder container, in your current container environment, to collect deployment objects and utilization metrics from Prometheus and;
- Configuring a connection between the Data Forwarder and Prometheus;
- Forwarding the collected data to your Densify instance.
After the Data Forwarder sends the data to your Densify instance, it terminates. Your Densify instance then performs the optimization analysis on the collected data and generates optimization recommendations. The Data Forwarder is scheduled to run periodically during the day.
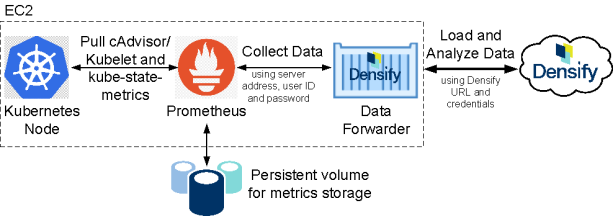
Densify's container data collection process consists of:
-
Deploy the Densify Data Forwarder using any one of the following methods:
- For Data Forwarder setup instructions using YAML files with a non-authenticated Prometheus, see Containers Data Forwarder with Prometheus.
- For Data Forwarder setup instructions using YAML files with an authenticated Prometheus, see Containers Data Forwarder with Authenticated Prometheus.
- For Data Forwarder setup instructions using a Helm chart, see Containers Data Forwarder Using a Helm Chart.
- If you are using Red Hat OpenShift and want to set up Data Forwarder using an Operator, see Containers Data Forwarder with Densify Operator.
- Once the Data Forwarder is able to send the collected container metrics,
Before you begin, refer to the prerequisites, listed below, for a list of container data collection requirements.
The following software is required for Densify container data collection and optimization.
- Densify account—Contact Densify for details of your subscription or sign up for a free trial.
- Kubernetes or OpenShift must be deployed.
- Running cAdvisor as part of the kubelet provides the workload and configuration data required by Densify.
- kube-state-metrics—This service monitors the Kubernetes API server and generates metrics from the various objects inside the individual Kubernetes components. This service provides orchestration and cluster level metrics such as deployments, pod metrics, resource reservation, etc. The collected metrics allow Densify to get a complete picture of how your containers are setup. i.e. Replica Sets, Deployments, Pod and Container Labels.
- Requires v1.5.0 or later. There are additional considerations when using v2.x. See below.
- https://github.com/kubernetes/kube-state-metrics
- Prometheus—Collects metrics from configured targets at given intervals. It provides the monitoring/data aggregation layer. It must be deployed and configured to collect kube-state-metrics and cAdvisor/kubelet metrics.
- Node Exporter—This is an agent deployed on every node to collect data about the nodes, on which the containers are running. This provides the required host-related metrics such as CPU, mem, network, etc.
The following item is not mandatory but provides additional environment information for Densify's container optimization analysis.
- Openshift-state-metrics—Expands upon kube-state-metrics by adding metrics for OpenShift-specific resources and provide additional details such as Cluster Resource Quotas (CRQ).
When deploying Prometheus and kube-state-metrics using a standard operator, some of the metrics that Densify needs for analysis may be excluded (i.e. on a deny list). Refer to Prometheus-Data.md for details of the required metrics.
Contact [email protected] for configuration details.
Additional Configuration for kube-state-metrics v2.x and Higher
Kubernetes Labels in kube-state-metrics
In kube-state-metrics v2.x features have been added to improve performance of both kube-state-metrics, itself and the Prometheus server that collects the resulting data.
One of these improvements affects the usage of Kubernetes object labels and annotations as Prometheus labels of the kube-state-metrics datapoints. In v2.x kube-state-metric, the default settings no longer include the collection of the Kubernetes object labels nor annotations and you need to configure the collection of these items using the command-line options.
Densify Container Data Collection and Kubernetes Labels
Though Densify's container data collection will work without the Kubernetes object labels as kube-state-metrics labels, you may want to enable the kube-state-metrics labels for the following use cases:
- Node group data collection requires the node labels.
- Data collection of other Kubernetes objects attempts to collect labels and annotations. These can be used to sort and filter containers in the UI or API and to create customized reports.
Node Groups
Node groups are not a Kubernetes feature, but rather are implemented by the public cloud provider's Kubernetes solution (e.g. AWS EKS, GCP GKE, Azure AKS). They are also used by 3rd party tools to provision the Kubernetes cluster (e.g. eksctl, kops).
Collecting node group data is only meaningful if you are able to match it to the public cloud provider's node group data (e.g. AWS ASG). In this case you need to enable node group data collection with kube-state-metrics version v2.x or higher.
- Add the following command-line argument to the kube-state-metrics container:
["--metric-labels-allowlist=nodes=[*]"]
If the performance of kube-state-metrics and/or Prometheus is a consideration, you can replace the wildcard (*)with a comma-separated list of specific node labels. This requires specific knowledge of the available node labels in the cluster, which depends on the cloud provider's Kubernetes solution and/or the 3rd party tool used to provision the cluster and their versions.
Labels of other Kubernetes objects
In addition to node labels, Densify attempts to collect the following data, which can be further used as sort/filter criteria and to generate custom reports:
Table: Optional Node Labels and Annotations
|
Labels |
Annotations |
|
|
|
|
- If you want to collect this data with kube-state-metrics v2.x or higher, add the following command-line arguments to the kube-state-metrics container:
["--metric-labels-allowlist=nodes=[*],namespaces=[*],pods=[*],deployments=[*],replicasets=[*],daemonsets=[*],statefulsets=[*],jobs=[*],cronjobs=[*],horizontalpodautoscalers=[*]", "--metric-annotations-allowlist=namespaces=[*]"]
Optionally, you can specify only the Kubernetes object labels that you need. Contact [email protected] for details.
Image Pull Policy
When deploying the forwarder, you need to ensure that the same version of the forwarder is deployed for all of your clusters.
The forwarder has the following 2 settings:
- image: densify/container-optimization-data-forwarder:3
- imagePullPolicy: Always
Since the imagePullPolicy is set to "Always" you do not need to update your forwarder instances since they will be updated automatically, if the image changes.